DeepSeek-R1 技术报告解读
DeepSeek-R1 技术报告解读
技术报告链接:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
0 编者按
自 OpenAI-o1 突破性构建复杂推理模型的技术范式以来,全球顶尖研究机构与科技企业相继投入这场认知智能的深层博弈。如月之暗面的 Kimi 探索版 (2024-10-11)、智谱的 GLM-Zero-Preview (2024-12-31)、谷歌的 Gemini 2.0 Flash Thinking (2024-12-24)、通义千问开源的 QwQ-32B-Preview (2024-11-28)。而现在这条赛道最大的赢家人尽皆知,DeepSeek-R1 不仅在排行榜上与 OpenAI-o1 不相上下,还以其优秀的思考和回复质量获得广大用户的喜爱。
在继续往下读之前,需要先了解一下 DeepSeek 系列产品的时间线:
- 2024-11-20:推理模型 DeepSeek-R1-Lite 预览版正式上线,使用强化学习训练,取得了媲美 o1-preview 的推理效果,并展现了 o1 没有公开的完整思考过程。
- 2024-12-26:DeepSeek-V3 正式发布并开源,MoE 模型,671B 参数,激活 37B,在 14.8T token 上进行了预训练,性能对齐海外领军闭源模型。
- 2025-1-20:DeepSeek-R1 发布,性能对标 OpenAI o1 正式版。并同步开源 DeepSeek-R1-Zero 和 DeepSeek-R1 模型权重,通过 DeepSeek-R1 的输出,蒸馏了 6 个小模型开源给社区。
整个时间顺序可以概括为:DeepSeek-R1-Lite(强化学习探索)\(\implies\) DeepSeek-V3(强大的基座)\(\implies\) DeepSeek-R1-Zero(大规模强化学习在大参数模型上的实践)\(\implies\) DeepSeek-R1(正式版推理模型)\(\implies\) 蒸馏小模型家族
下面本文以 DeepSeek-R1 官方技术报告为研究范本,系统解构其架构设计范式与技术实现路径。
1 DeepSeek 的核心贡献
1.1 后训练(Post-Training):基座模型上的大规模强化学习
- 突破性地绕过了监督微调(SFT)的数据依赖,开创性地采用纯强化学习(RL)范式对基座模型进行直接优化。让模型自己探索解决复杂问题的思维链(CoT),最终成功研发出具有自我验证、自我反思和生成长思维链的能力的 DeepSeek-R1-Zero。更值得关注的是,这是全球范围内首个公开验证大模型无需监督微调数据、仅通过强化学习即可获得高阶推理能力的实证研究,为后续的算法演进提供了可扩展的理论框架。
- 阐述了 DeepSeek-R1 的开发流程。包括两个强化学习阶段来优化推理格式和对齐人类偏好,和两个监督微调阶段强化模型在推理场景和不需要推理场景下的表现。这种训练范式将为更强大的工业级模型研发提供可复现的实践框架。
1.2 蒸馏(Distillation):小模型也有大能量
- 验证了大参数量模型的推理范式可通过蒸馏有效迁移至轻量化模型,相较于对小模型直接进行强化学习方案,这一技术路径展现出显著的性能优势。未来 DeepSeek-R1 及其 API 可以用来蒸馏更多性能强悍的小模型。
- 基于 DeepSeek-R1
生成的推理数据微调了多个小模型。这些经过蒸馏处理的模型在多个权威基准测试中展现出超越预期的表现:其中
DeepSeekR1-Distill-Qwen-7B 在 AIME 2024 评测中取得 55.5%
的准确率,
打脸反超了 QwQ-32B-Preview 模型;DeepSeek-R1-Distill-Qwen-32B 在 AIME 2024 得分 72.6%,MATH-500 得分 94.3%,LiveCodeBench 得分 57.2%。不仅大幅刷新开源模型的性能记录,更在技术上对标了商业级的 o1-mini 模型。目前,基于 Qwen2.5 和 Llama3 架构的蒸馏模型(涵盖 1.5B、7B、8B、14B、32B 及 70B 参数规模)已向开发者社区全面开源。
2 方法
2.1 概述
传统方法高度依赖海量监督数据来提升模型性能,本研究发现即使不使用监督微调,直接大规模强化学习即可提升模型的推理能力。而若采用“冷启动→强化学习”两阶段策略(即先用少量监督数据微调,再实施强化学习),能实现性能的进一步跃升。下面将介绍:
- DeepSeek-R1-Zero:零样本启动的纯强化学习;
- DeepSeek-R1:先用数千条思维链样本来监督微调冷启动,再强化学习;
- 利用知识蒸馏,把 DeepSeek-R1 的推理能力迁移到更小的 Dense 模型。
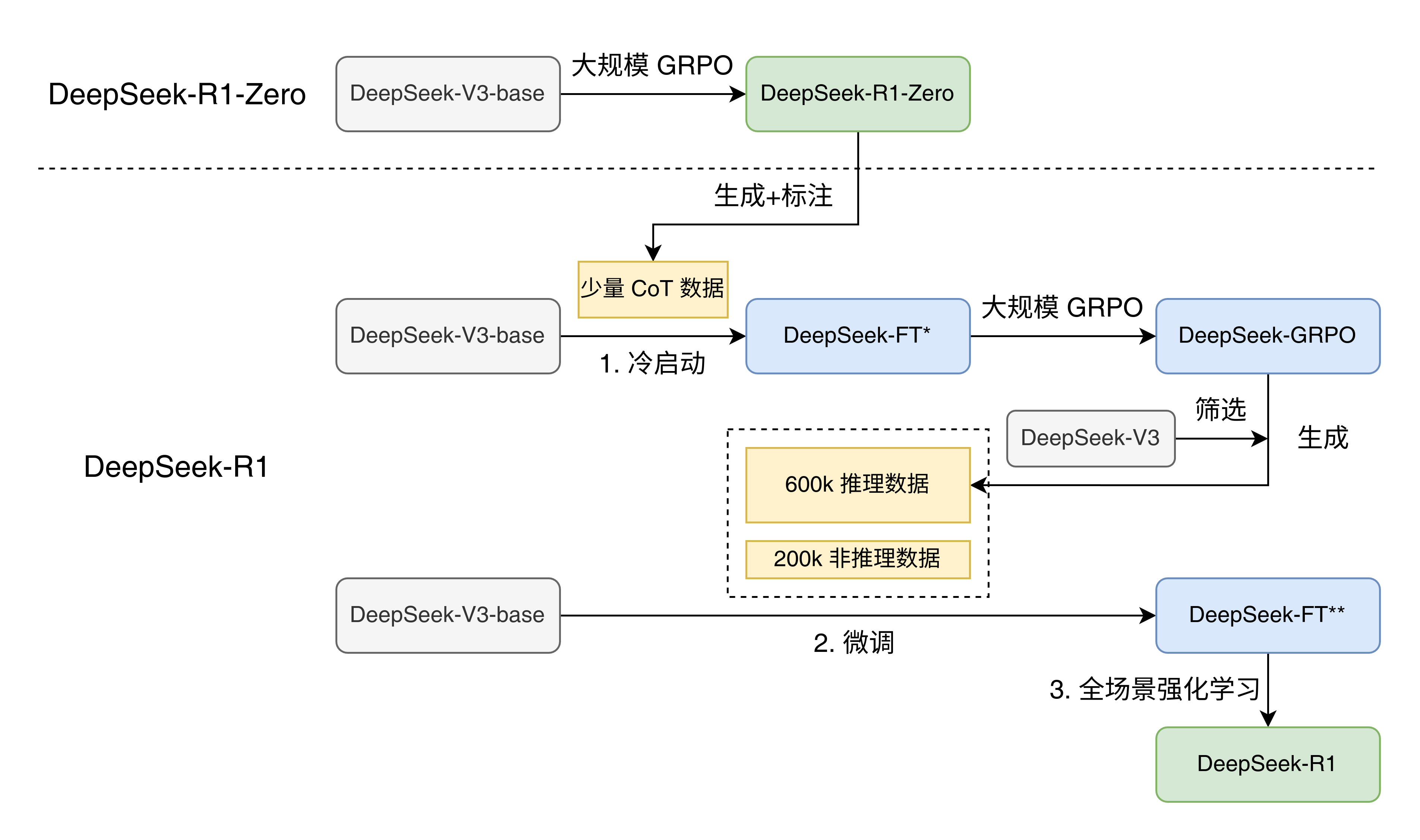
DeepSeek 训练流程总结:
- DeepSeek-V3-base 模型进行 CoT 数据微调的冷启动得到小规模微调模型(DeepSeek-FT*);
- DeepSeek-V3-base 模型进行 2 epochs 的大规模微调得到推理模型(DeepSeek-FT**);
- 全场景强化学习,进一步优化复杂推理和无害性等能力。
2.2 DeepSeek-R1-Zero:在基座模型上的强化学习
大量研究表明,强化学习能有效提升大模型的逻辑推理能力。但现有方法严重依赖标注完备的监督数据,而高质量标注集的构建往往伴随高昂的时间和人力成本。本研究突破性地探索了大模型在零监督数据条件下,通过纯强化学习范式自主进化推理能力的可行性路径。
2.2.1 强化学习算法
组相对策略优化(Group Relative Policy Optimization, GRPO)
针对强化学习训练成本高的问题,采用最新提出的群体相对策略优化算法(GRPO)。该方法,摒弃了传统方法中与策略模型规模相当的评论家模型,转而从群体得分中来估算基准值。具体来说,对于每一个问题 \(q\),GRPO 从旧策略 \(\pi_{\theta_{old}}\) 中采样出一组输出 \(\{o_1, o_2, \dots, o_{G}\}\),然后通过最大化以下式子来优化策略模型 \(\pi_{\theta}\): \[ \begin{aligned} \mathcal{F}_{GRPO}(\theta) & = \mathbb{E}\left[ q \sim P(Q), \{o_i\}_{i=1}^{G} \sim \pi_{\theta_{old}}(O|q) \right] \\ & \frac{1}{G}\sum\limits^{G}_{i=1}\left(\min\left(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}A_i, \mathrm{clip}\left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}, 1-\varepsilon, 1+\varepsilon\right) A_i\right) - \beta \mathbb{D}_{KL}(\pi_{\theta}, \pi_{ref})\right), \\ \mathbb{D}_{KL}(\pi_{\theta}, \pi_{ref}) &= \frac{\pi_{ref}(o_i|q)}{\pi_{\theta}(o_i|q)} - \log \frac{\pi_{ref}(o_i|q)}{\pi_{\theta}(o_i|q)} - 1 \end{aligned} \] 其中 \(\varepsilon\) 和 \(\beta\) 是超参数,\(A_i\) 是优势(adventage),用每一组输出对应的奖励(reward)来计算: \[ A_{i} = \frac{r_i - \mathrm{mean}(\{r_1, r_2, ..., r_G\})}{\mathrm{std}(\{r_1, r_2, ..., r_G\})} \]
2.2.2 奖励模型(Reward Model)
强化学习的训练框架中,奖励机制作为训练信号的核心来源,主导着模型的优化方向。训练 DeepSeek-R1-Zero 时,采取了基于规则的奖励系统,主要包含两个部分:
- 准确度奖励:这一机制用于评估回复的正确性。例如,在解答数学题时,模型需要以特定格式呈现最终答案(如将答案放在方框
\box{}内),以便通过规则自动识别和验证。同样地,在解决 LeetCode 问题时,可以通过编译器运行测试用例来检验代码的正确性。 - 格式奖励:除了准确度外,还设计了格式奖励来强迫模型把思考过程放到
<think>和</think>中间。
在训练 DeepSeek-R1-Zero 时,没有采用神经网络模型的输出作为奖励机制。研究表明,在大规模强化学习过程中,使用神经网络作为奖励模型可能会引发“奖励劫持”(reward hacking)现象,这会增加额外的训练资源需求,使整个训练过程变得更加复杂。
2.2.3 训练模板
A conversation between User and Assistant. The user asks a question,and the Assistant solves it. The assistant first thinks about thereasoning process in the mind and then provides the user with theanswer. The reasoning process and answer are enclosed within<think> </think> and <answer> </answer> tags,respectively, i.e., <think> reasoning process here </think><answer> answer here </answer>. User:
DeepSeek-R1-Zero 的训练模板:在训练时 prompt 被替换成推理问题。
训练 DeepSeek-R1-Zero 时,首先设计了明确的指令模板来引导模型。如上面所示,模板要求 DeepSeek-R1-Zero 先生成推理过程再生成最终答案。有意限制成这种格式是为了避免产生任何特定内容长的偏差(例如强制要求进行反思性推理或推崇特定的问题解决策略),从而确保能准确观察模型在强化学习过程中的自然演变。
2.3 DeepSeek-R1:带冷启动的强化学习
DeepSeek-R1-Zero 抛出了两个极具探索价值的核心命题:
- 基于有限的高质量训练数据进行冷启动,能否提升模型推理能力或显著加速收敛过程?
- 能否构建既能生成清晰连贯的思维链,又具备强大通用能力的模型?
为系统攻克这些技术挑战,DeepSeek-R1 训练框架应运而生。整个过程包含四个阶段:
2.3.1 冷启动
为解决基础模型在强化学习早期阶段的不稳定冷启动问题,DeepSeek-R1 的训练中进行了一些改进:先构建高质量的长思维链数据微调模型,再进行后续的强化学习。收集这些数据的方法是:使用长思维链数据作为少样本的样例,直接让 DeepSeek-R1-Zero 生成有反思和验证过程的详细答案,接着把输出处理成可读的格式,最后让人类对结果进一步标注修改。
本次收集了几千条冷启动数据来微调 DeepSeek-V3-Base,和 DeepSeek-R1-Zero 的流程相比,这样做的好处包括:
- 可读性:DeepSeek-R1-Zero 的关键问题就是可读性很差,回复可能夹杂多种语言,也不会使用 markdown。而冷启动数据则不会包含可读性查的回复,并且在每一个回复后面加上了总结。具体的回复格式定义为 |special_token|<reasoning_process>|special_token|<summary>,其中 <reasoning_process> 是思维链,<summary> 是思考过程的总结。
- 潜在因素:多了人类友好的冷启动数据微调,最终的效果要比 DeepSeek-R1-Zero 更好。表明对于推理模型来说,迭代式训练是更好的训练方式。
2.3.2 面向推理的强化学习
DeepSeek-V3-Base 在冷启动数据微调后,遍进入了 DeepSeek-R1-Zero 同款大规模强化学习阶段。本阶段聚焦于提升模型的推理能力,特别是代码、数学、科学和逻辑推理这种问题和答案都比较明确的场景。训练过程中发现思维链经常出现语言混杂的现象,特别是当提示词(prompt)包含多语言的时候。为了缓解这个问题,在强化学习阶段还引入了语言一致性奖励机制, 即计算生成思维链中语言的比例。虽然消融实验表明这种对齐方式会略微降低模型性能,但是却对齐了人类偏好,增强了可读性。把推理准确率和语言一致性的直接求和就得到了最终的奖励,然后在微调后的模型上进行强化学习,直到模型在推理问题上趋于收敛。
2.3.3 拒绝采样和监督微调
面向推理的强化学习收敛后,得到的模型会被用于收集后续监督微调的数据。和一开始主要是推理问题的冷启动数据不同,这次的数据包含了其他领域以提高模型在写作、角色扮演和其他通用任务上的能力。具体来说,微调数据包含以下两个部分:
推理数据
收集推理任务的提示词,然后对上一步的模型进行拒绝采样来生成推理路径。先前只收集了能够能够通过基于规则的奖励机制来评价的数据。然而这次结合了其他的数据,其中有一些需要通过给 DeepSeek-V3 提供模型输出和标准答案来打分给出奖励。此外,因为模型输出有时会包含噪声可读性差,仍然需要过滤掉那些语言夹杂、长篇大论、包含代码块的思维链。对每一个提示词会生成多个答案并留下正确的那个。最终收集了 600k个推理相关的训练样本。
非推理数据
写作、事实问答、自我认知和翻译这样的非推理数据来则自于 DeepSeek-V3 的微调数据集。对于某些非推理任务,会通过设计提示词让 DeepSeek-V3 来生成思维链。 而对于 “hello” 这样的更简单的问题,则不会生成思维链。最后收集了大约 200k 推理无关的训练数据。
以上共 800k 数据在 DeepSeek-V3-Base 上微调了两轮(epoch)。
2.3.4 全场景强化学习
经过二次强化学习优化,模型的实用性与安全性得到显著提升,同时推理能力进一步增强。针对数学、代码及逻辑推理类数据,沿用DeepSeek-R1-Zero 的基于规则的奖励机制;对于通用场景数据,则使用奖励模型来捕捉复杂情境中的人类偏好特征,训练过程遵循 DeepSeek-V3 训练框架的提示词和偏好分布。在实用性角度,聚焦输出结论的有效性与场景相关性,通过优化评估指标突出用户需求导向,最大限度降低对推理过程的过度干预;在安全性角度,建立全流程监测机制,对推理过程和最终结论实施校验,精准识别并修正潜在风险点、偏见倾向及有害内容表达。通过多维奖励机制的作用与多样化数据集的训练,最终形成的模型在保持优秀推理能力的同时,兼备实用性与安全性。
2.4 蒸馏:赋予小模型推理能力
为了让更多小尺寸模型也能具备 DeepSeek-R1 这样的推理能力,直接用其生成的 800k 数据微调了 Qwen 和 Llama 系列小模型。最终发现直接蒸馏极大提高了小尺寸模型的推理能力。用到的基座模型有 Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B 和 Llama-3.3-70B-Instruct。选用 Llama-3.3 的原因是它的推理能力比 Llama-3.1更强。
在蒸馏策略设计上,仅采用监督微调而未引入强化学习,尽管后者存在进一步优化潜力。因为原本目标只是证明蒸馏技术的有效性,后续的强化学习就留给广大开发者社区去探索了
3 总结
以上翻译自 DeepSeek-R1 的技术报告的主要贡献和训练技术部分,并没有设计实验结论等内容,如需了解可以自行阅读。下面提出我个人的一些思考:
3.1 DeepSeek-R1 的幻觉危机
Vectara 幻觉榜单指出 DeepSeek-R1 的幻觉非常严重,这里截取一部分来对比:
| Model | Hallucination Rate | Factual Consistency Rate | Answer Rate | Average Summary Length (Words) |
|---|---|---|---|---|
| Google Gemini-2.0-Flash-001 | 0.7 % | 99.3 % | 100.0 % | 65.2 |
| OpenAI-o3-mini-high-reasoning | 0.8 % | 99.2 % | 100.0 % | 79.5 |
| Zhipu AI GLM-4-9B-Chat | 1.3 % | 98.7 % | 100.0 % | 58.1 |
| OpenAI-o1-mini | 1.4 % | 98.6 % | 100.0 % | 78.3 |
| GPT-4o | 1.5 % | 98.5 % | 100.0 % | 77.8 |
| OpenAI-o1 | 2.4 % | 97.6 % | 99.9 % | 73.0 |
| DeepSeek-V2.5 | 2.4 % | 97.6 % | 100.0 % | 83.2 |
| Qwen2.5-32B-Instruct | 3.0 % | 97.0 % | 100.0 % | 67.9 |
| Qwen2.5-Max | 2.9 % | 97.1 % | 88.8 % | 90.4 |
| DeepSeek-V3 | 3.9 % | 96.1 % | 100.0 % | 88.2 |
| Llama-3.3-70B-Instruct | 4.0 % | 96.0 % | 100.0 % | 85.3 |
| Qwen2.5-72B-Instruct | 4.3 % | 95.7 % | 100.0 % | 80.0 |
| DeepSeek-R1 | 14.3 % | 85.7 % | 100.0% | 77.1 |
| Qwen-QwQ-32B-Preview | 16.1 % | 83.9 % | 100.0 % | 201.5 |
| Qwen2.5-0.5B-Instruct | 25.2 % | 74.8 % | 100.0 % | 72.6 |
相较于同架构的上一代 DeepSeek-V3 模型,DeepSeek-R1 的幻觉尤其严重,Qwen 的 QwQ-32B-Preview 更低,那是否说明无监督的大规模强化学习训练出来的推理模型注定会存在幻觉?似乎是有点道理,但是 OpenAI 的 o3、o1 系列模型幻觉显著更低。看来 OpenAI 可能有未公开的缓解幻觉的方法。那么如何缓解推理模型的幻觉,将是一个值得研究的问题。